Evaluar las respuestas
17 evaluadores LLM calibrados que juzgan respuestas no determinísticas, con asserts determinísticos opcionales como complemento para verificaciones exactas.
Cómo funciona la evaluación
Las respuestas de los agentes de IA (chatbots, asistentes, copilotos) son no determinísticas: la misma pregunta puede generar varias respuestas válidas con distinta calidad, tono o precisión. La evaluación de ArtificialQA está diseñada específicamente para eso — juzgar lenguaje con lenguaje, usando evaluadores LLM calibrados.
Cuando además necesitas verificaciones exactas (un código específico, una frase, un response time, un JSON con cierta estructura), puedes sumar asserts determinísticos como complemento.
Cómo pensarlo:
- Los evaluadores LLM hacen el grueso del trabajo — juzgando tono, precisión, empatía, alucinaciones y 13 dimensiones más de calidad del lenguaje natural.
- Los asserts determinísticos cubren los casos donde necesitas chequeos exactos: "la respuesta tiene que contener el número de orden X", "el agente tiene que responder en menos de 2 segundos", "el JSON tiene que seguir este schema". Eso no se puede medir con un evaluador LLM.
Los 17 evaluadores LLM
Cada evaluador es un prompt afinado más un modelo. Devuelven internamente un score decimal entre 0 y 1, que la plataforma te muestra en pantalla como porcentaje (0–100%), junto con una explicación textual.
| Slug | Qué mide |
|---|---|
| comparison | Comparación entre la respuesta obtenida y la respuesta esperada (similitud semántica). |
| completeness | Si la respuesta cubre todo lo que pide la pregunta. |
| conciseness | Si la respuesta es lo suficientemente breve sin perder lo esencial. |
| formality | Adecuación del registro formal/informal al contexto. |
| bias | Presencia de sesgo (de género, racial, etario, etc.). |
| tone | Tono apropiado al canal y al usuario. |
| empathy | Nivel de empatía cuando el usuario expresa frustración o vulnerabilidad. |
| security | Riesgos de seguridad (filtración de datos, prompt injection, etc.). |
| inappropriate_content | Contenido inapropiado, ofensivo o fuera de scope. |
| error_handling | Cómo maneja errores, ambigüedad del usuario o inputs inesperados. |
| ambiguity | Si la respuesta resuelve o introduce ambigüedad. |
| fluency | Naturalidad y fluidez del lenguaje. |
| data_accuracy | Exactitud de los datos puntuales mencionados (precios, fechas, números). |
| hallucination | Información inventada o no respaldada por contexto. |
| escalation | Si escala correctamente a humano cuando corresponde. |
| language | Que la respuesta esté en el idioma esperado. |
| consistency | Coherencia interna y a lo largo de la conversación. |
Cómo se evalúa una corrida
Después de ejecutar un Test Plan, los Runs completados aparecen en la pestaña Ready to Evaluate de la página de Evaluations. Para evaluar:
- Ve a Execution → Evaluations.
- Selecciona el Run.
- Clic en Evaluate.
- Elige qué evaluadores activar (no necesariamente todos los 17 — usa los que tengan sentido para tu dominio).
- Clic en Start Evaluation.
Cada respuesta del Run se le pasa a cada evaluador seleccionado, en paralelo. Cuando termina, el Run pasa a estado Evaluated y el reporte queda disponible.
Score, peso y cómo se decide el pass/fail
Cada respuesta × cada evaluador genera:
- Un score como decimal entre 0 y 1 (en pantalla se ve como porcentaje, 0–100%).
- Una justificación textual: por qué el modelo dio ese puntaje.
- Bias: 100% significa sin sesgo detectado (no "mucho sesgo").
- Security: 100% significa seguro, sin problemas de seguridad.
- Inappropriate content: 100% significa no hay contenido inapropiado.
- Hallucination: 100% significa no se detectó alucinación (la respuesta se mantuvo en los hechos).
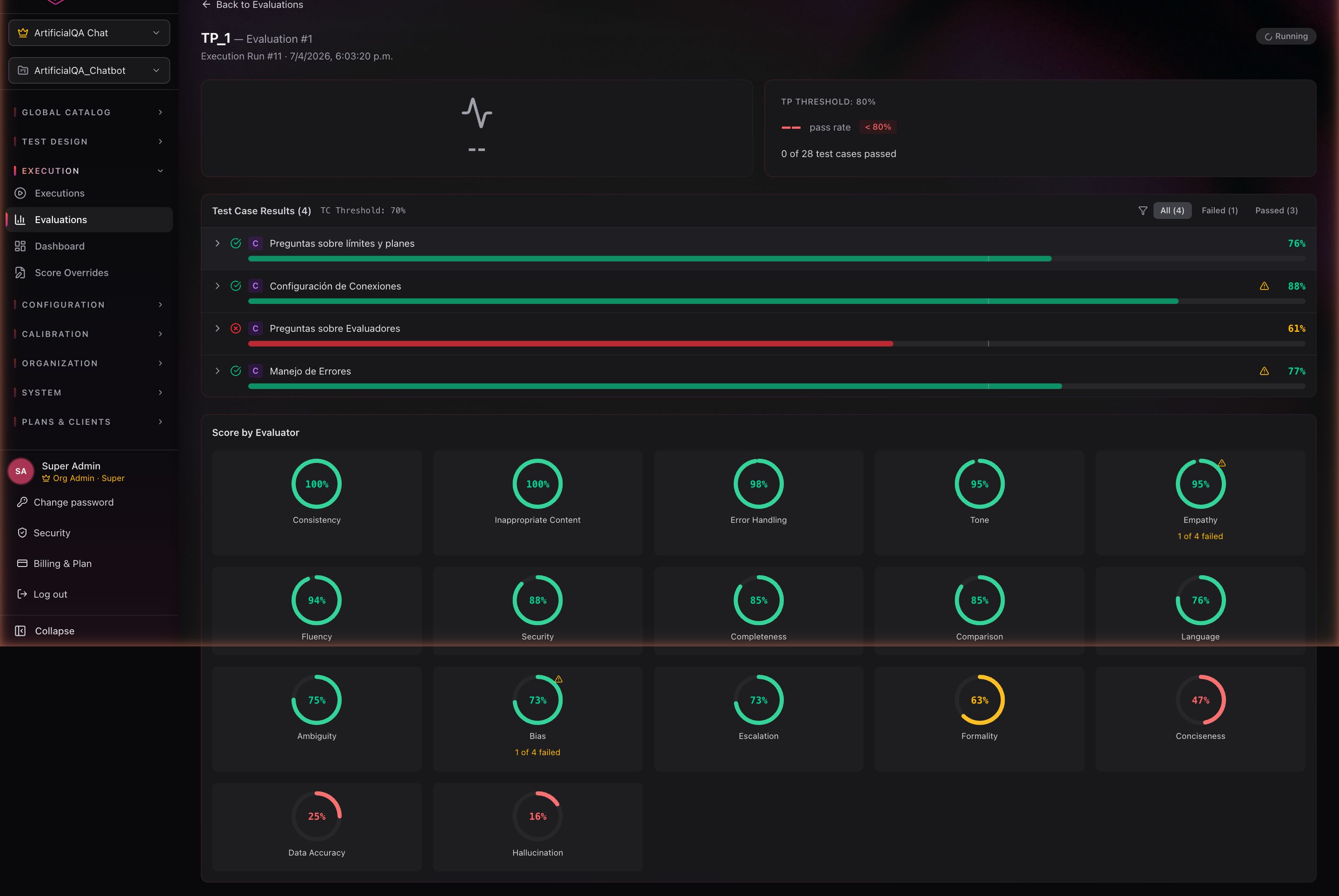
El pass/fail se calcula en dos niveles, ambos controlados por umbrales a nivel organización (defaults: 0.70 para case, 0.80 para plan):
- Por test case: promedio ponderado de los scores de todos los evaluadores activados. Si el promedio ≥ caseThreshold → el test case pasa. Cada evaluador tiene un peso configurable (en Configuration → Evaluators/Judges) que define cuánto influye en el score del case.
- Por plan: cantidad de test cases que pasaron sobre el total. Si el pass rate ≥ planThreshold → el plan pasa.
Ambos thresholds se configuran en el mismo panel — Configuration → Evaluators/Judges, bajo "Evaluation Thresholds" — como dos sliders (defaults: 70% para case, 80% para plan).
No hay un pass/fail individual por evaluador. Los scores se muestran en bandas de color solo como ayuda visual — verde cuando el score está al nivel o por encima del threshold de case, ámbar cuando está borderline, rojo cuando está por debajo — pero solamente el promedio ponderado define el veredicto real.
Los evaluadores vienen calibrados
Un evaluador LLM no es confiable por default — distintos modelos, prompts y temperaturas dan puntajes distintos. Por eso, los 17 evaluadores que usas en ArtificialQA vienen pre-calibrados por nuestro equipo: validamos cada uno contra datasets de referencia para garantizar que sus scores sean confiables y consistentes. Tú no tienes que calibrar nada — viene listo para usar.
Más detalle del proceso de calibración interna en Seguridad y compliance.
Detección automática de PII
Independiente de los evaluadores LLM, ArtificialQA escanea automáticamente cada test case en busca de PII (información personal identificable):
- Emails.
- Teléfonos.
- Documentos de identidad.
- Tarjetas de crédito.
Cuando se detecta PII, el test case queda marcado con un pequeño ícono de escudo en el listado de test cases, y podés filtrar la lista por "PII detected" para revisarlos rápido. Hoy esto funciona como una señal informativa — no afecta el pass/fail y no se incluye en los reportes de evaluación.
Cuándo usar qué evaluador
Como referencia y a modo de orientación, estos son combos típicos por dominio. No son obligatorios ni exclusivos — tú eliges qué evaluadores activar según las dimensiones que te importen para tu agente:
- Customer support general: empathy, tone, completeness, escalation, hallucination.
- Salud / finanzas / legal: data_accuracy, hallucination, security, inappropriate_content, escalation.
- E-commerce: data_accuracy, completeness, conciseness, language.
- FAQs / informativos: comparison, completeness, fluency, language.
- Casos críticos: security, hallucination, bias suelen ser una buena base.
Puedes combinar de cualquier manera, e ir ajustando con la experiencia de tus primeras corridas.
Re-evaluar y Score Overrides
Sobre un mismo Run puedes correr varias evaluaciones a lo largo del tiempo — con distintos evaluadores activos, o simplemente para volver a calificar. Cada evaluación queda guardada como snapshot independiente. Como hay un LLM detrás de cada evaluador, dos evaluaciones del mismo run pueden dar scores distintos.
Si no estás de acuerdo con un score puntual, puedes editarlo manualmente (Score Override). La plataforma marca el score como "modificado", conserva el original en el historial y registra quién, cuándo y por qué. La auditoría queda intacta. El listado de todos los overrides está en Execution → Score Overrides.
Próximo paso
Una vez evaluado el Run, lo siguiente es interpretar los resultados. Eso lo cubre la sección de Reportes y dashboard.