Reportes y dashboard
Cómo leer los resultados de una evaluación, dónde mirar las tendencias y cómo exportar reportes para auditoría.
Dashboard general
El Dashboard es la vista de entrada después del login. Resume lo que está pasando en tu organización:
- Runs recientes con su estado y score general.
- Tendencia de calidad a lo largo del tiempo (los últimos N runs).
- Evaluaciones recientes con resumen de pass rate.
El uso de tu plan (tokens consumidos, generaciones IA, etc.) y la gestión de plan se ven en Billing & Plan — ver Planes y pricing → Billing & Plan.
Evaluation Report (por Run)
Cada Run evaluado genera un Evaluation Report. Ve a Execution → Evaluations y haz clic en el run.
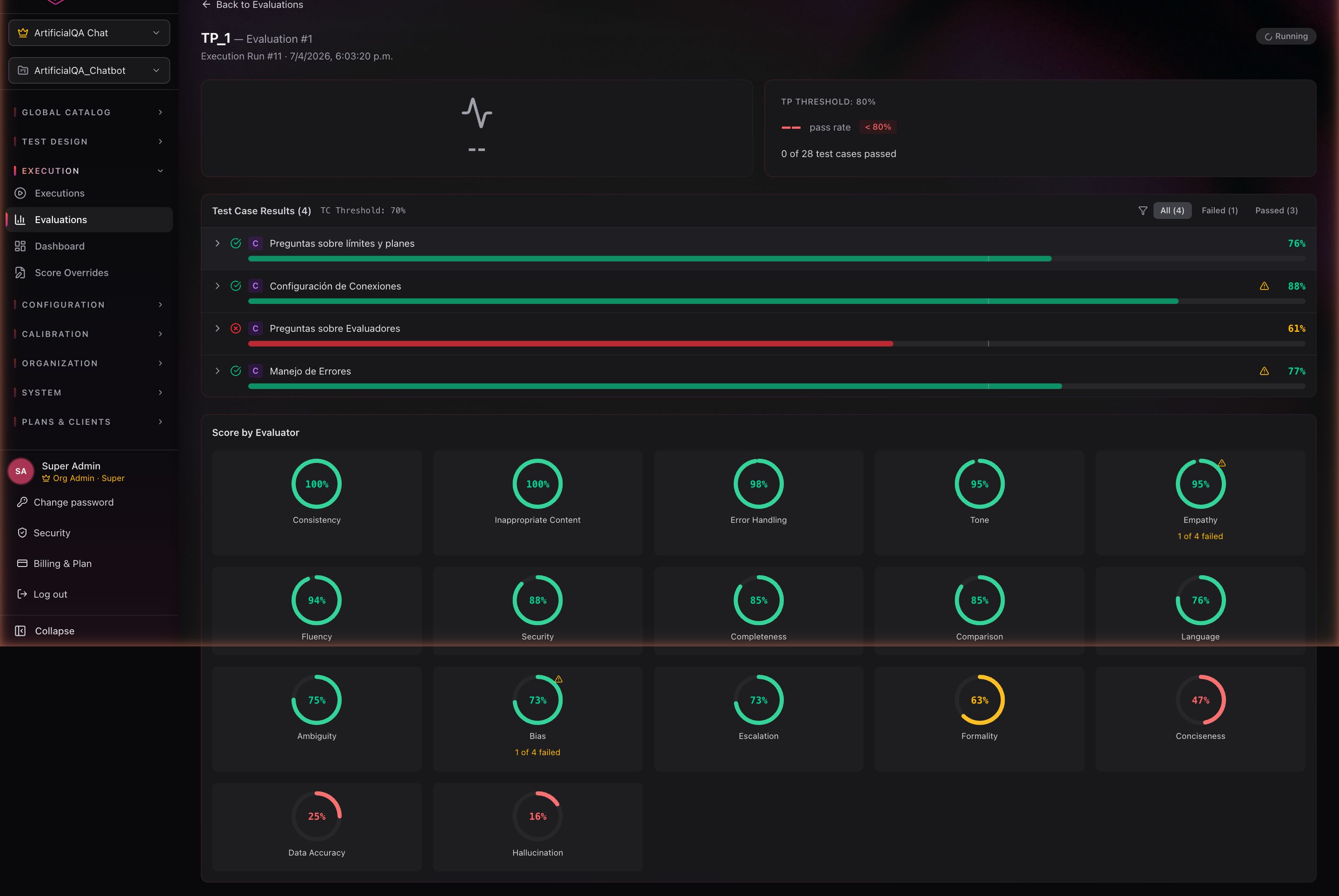
Qué muestra
- Score general: promedio ponderado de todos los evaluadores.
- Pass rate: % de casos que pasaron todos los asserts hard.
- Performance por evaluador: cada uno de los evaluadores activados con su score promedio y desviación.
- Detalle por test case: para cada caso, el input, la respuesta del bot, los asserts y los scores de cada evaluador con justificación textual.
- Casos fallidos destacados: los que necesitan revisión humana.
Exportar a PDF
Botón PDF Report en la parte superior. Genera un PDF con:
- Resumen ejecutivo (con header de tu organización).
- Score general y pass rate.
- Performance por evaluador (gráfico de barras).
- Detalle de casos fallidos.
- Metadata del run: fecha, agente, suite, evaluadores activados.
El PDF está pensado para circular dentro del equipo o como entregable a stakeholders.
Reporte mejorado con IA (Enterprise)
Solo en plan Enterprise. Sobre el Evaluation Report, la plataforma agrega un análisis automático con IA:
- Resumen ejecutivo textual de toda la corrida (3–5 párrafos), con conclusiones, principales hallazgos y recomendaciones.
- Análisis por evaluador: para cada uno de los evaluadores activados, una explicación textual de qué patrones se vieron, qué cosas funcionan bien, qué cosas habría que revisar.
- En español o inglés según se configure.
El reporte mejorado se anexa al PDF estándar.
Tendencias y comparativa entre runs
El dashboard muestra la evolución del score general a lo largo de los runs. Esto te permite ver si la calidad está mejorando, manteniéndose o degradándose entre releases.
Cada run individual se puede inspeccionar y exportar.
Snapshots inmutables y reproducibilidad
El sistema mantiene dos niveles de "fotos" inmutables:
- Cada Run guarda un snapshot de las respuestas que dio el agente de IA en ese momento (input, response, tiempos, logs). Una vez ejecutado, ese run no se modifica nunca más.
- Cada Evaluation guarda un snapshot de los scores y justificaciones que dieron los evaluadores en ese momento. Una vez evaluada, esa evaluación tampoco se modifica.
Esto significa que un reporte generado hace 6 meses sigue idéntico hoy, aunque hayas cambiado los Test Cases, el agente de IA o los evaluadores. Es la base de la auditabilidad.
Reproducibilidad: cuidado con esperar resultados idénticos
El snapshot es inmutable, pero si re-ejecutas el mismo Test Plan, las respuestas del agente de IA pueden ser distintas porque hay un LLM detrás del agente de IA, y los LLMs no son deterministas. Lo mismo aplica a evaluación: si vuelves a evaluar el mismo Run, los scores pueden cambiar porque también hay un LLM detrás de cada evaluador.
Sobre un mismo Run puedes correr N evaluaciones distintas a lo largo del tiempo (con distintos evaluadores activos, o simplemente para volver a calificar). Todas quedan guardadas como snapshots independientes.
Score Overrides: corrección manual con auditoría
Si no estás de acuerdo con el score que dio un evaluador para un caso puntual, puedes editarlo manualmente. La plataforma:
- Marca el resultado como "modificado" (queda visible en el reporte que ese score fue corregido).
- Conserva el score original en el historial.
- Registra quién hizo la modificación, cuándo, y la nota explicativa.
El listado completo de overrides aplicados en tu organización se ve en Execution → Score Overrides. Esto te permite mantener auditoría completa: las modificaciones existen pero quedan trazadas.
Cómo leer un score
Los evaluadores devuelven valores entre 0 y 1 internamente, pero la plataforma los muestra en pantalla como porcentaje (0–100%) para que sean más fáciles de leer. Como guía general:
- 90–100%: excelente. La respuesta cumple plenamente la dimensión evaluada.
- 70–90%: aceptable. Cumple lo esperado con observaciones menores.
- 50–70%: dudoso. Hay problemas claros pero no bloqueantes.
- 0–50%: falla. La respuesta no cumple lo esperado en esa dimensión.
El umbral pass/fail es configurable por evaluador en Configuration → Evaluators/Judges. Cada evaluador trae un threshold razonable por default que puedes ajustar a tu criterio.
Compartir un reporte
Hay dos formas:
- PDF: exportás el reporte y lo enviás por mail o Slack.
- API (Enterprise): consumís los resultados desde tu pipeline.
Los miembros de tu organización también pueden abrir un run directamente por URL — copiala de la barra de direcciones del browser y pasala; quien la reciba tiene que estar logueado y ser miembro de la misma organización para verlo. Hoy no hay un botón dedicado de "Compartir".
Próximo paso
Si quieres ver cómo conectar ArtificialQA con otras herramientas (CI, gestores de tickets, notificaciones), pasa a la sección de Integraciones.