Evaluating the responses
17 calibrated LLM evaluators that judge non-deterministic responses, with optional deterministic asserts as a complement for exact checks.
How evaluation works
Responses from AI agents (chatbots, assistants, copilots) are non-deterministic: the same question can produce several valid answers with different quality, tone, or accuracy. ArtificialQA's evaluation is built specifically for that — judging language with language, using calibrated LLM evaluators.
When you also need exact checks (a specific code, a phrase, a response time, a JSON shape), you can add deterministic asserts as a complement.
How to think about it:
- The LLM evaluators do most of the work — judging tone, accuracy, empathy, hallucinations and 13 other dimensions of natural-language quality.
- Deterministic asserts cover the cases where you need exact checks: "the response must contain order number X", "the agent must respond in under 2 seconds", "the JSON payload must follow this schema". You can't measure these with an LLM judge.
The 17 LLM evaluators
Each evaluator is a tuned prompt plus a model. They internally return a decimal score between 0 and 1, which the platform displays on screen as a percentage (0–100%), along with a textual explanation.
| Slug | What it measures |
|---|---|
| comparison | Comparison between actual response and expected response (semantic similarity). |
| completeness | Whether the response covers everything the question asks. |
| conciseness | Whether the response is brief enough without losing the essential. |
| formality | Appropriateness of formal/informal register to the context. |
| bias | Presence of bias (gender, racial, age, etc.). |
| tone | Tone appropriate to channel and user. |
| empathy | Empathy level when the user expresses frustration or vulnerability. |
| security | Security risks (data leakage, prompt injection, etc.). |
| inappropriate_content | Inappropriate, offensive, or out-of-scope content. |
| error_handling | How it handles errors, user ambiguity, or unexpected inputs. |
| ambiguity | Whether the response resolves or introduces ambiguity. |
| fluency | Naturalness and fluency of the language. |
| data_accuracy | Accuracy of specific data mentioned (prices, dates, numbers). |
| hallucination | Made-up information not backed by context. |
| escalation | Whether it correctly escalates to human when appropriate. |
| language | That the response is in the expected language. |
| consistency | Internal coherence and across the conversation. |
How a run is evaluated
After running a Test Plan, completed Runs appear in the Ready to Evaluate tab on the Evaluations page. To evaluate:
- Go to Execution → Evaluations.
- Select the Run.
- Click Evaluate.
- Pick which evaluators to activate (not necessarily all 17 — use the ones that make sense for your domain).
- Click Start Evaluation.
Each Run response gets passed to each selected evaluator, in parallel. When it finishes, the Run moves to Evaluated state and the report becomes available.
Score, weight, and how pass/fail is decided
Each response × each evaluator produces:
- A score as a decimal between 0 and 1 (shown on screen as a percentage, 0–100%).
- A textual justification explaining why the model gave that score.
- Bias: 100% means no bias detected (not "lots of bias").
- Security: 100% means safe, no security issues.
- Inappropriate content: 100% means no inappropriate content.
- Hallucination: 100% means no hallucination detected (the response stuck to the facts).
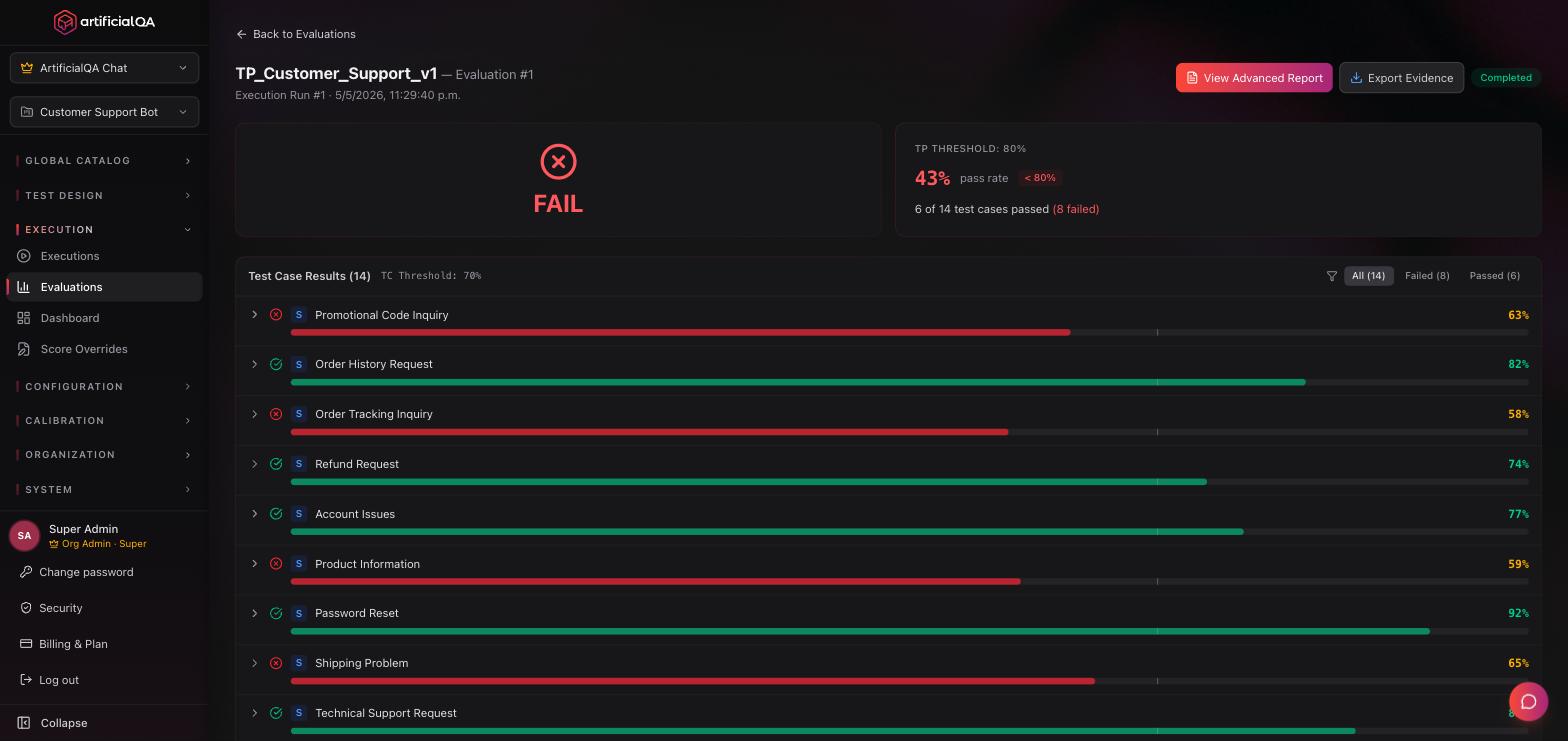
Pass/fail is computed at two levels, both controlled by organization-level thresholds (defaults: 0.70 for case, 0.80 for plan):
- Per test case: weighted average of all activated evaluator scores. If avg ≥ caseThreshold → the test case passes. Each evaluator has a configurable weight (set at Configuration → Evaluators/Judges) that determines how much it influences the case score.
- Per plan: number of passed test cases divided by total. If pass rate ≥ planThreshold → the plan passes.
Both thresholds are configured in the same panel — Configuration → Evaluators/Judges, under "Evaluation Thresholds" — as two sliders (defaults: 70% for case, 80% for plan).
There is no individual pass/fail per evaluator. Scores are shown in color bands purely as a visual aid — green when the score is at or above the case threshold, amber for borderline values, red below — but only the weighted average drives the actual verdict.
The evaluators come pre-calibrated
An LLM evaluator isn't trustworthy by default — different models, prompts, and temperatures yield different scores. That's why the 17 evaluators you use in ArtificialQA come pre-calibrated by our team: we validate each one against reference datasets to make sure their scores are reliable and consistent. You don't have to calibrate anything — it's ready to use.
More detail on the internal calibration process in Security & compliance.
Automatic PII detection
Independent of the LLM evaluators, ArtificialQA automatically scans every test case for PII (personally identifiable information):
- Emails.
- Phone numbers.
- ID documents.
- Credit cards.
When PII is detected, the test case is marked with a small shield icon in the test case list, and you can filter the list by "PII detected" to review them quickly. Today this works as an advisory signal — it doesn't affect pass/fail and isn't included in evaluation reports.
When to use which evaluator
For reference and as a guideline, these are typical combos by domain. They are not mandatory or exclusive — you choose which evaluators to activate based on the dimensions that matter for your agent:
- General customer support: empathy, tone, completeness, escalation, hallucination.
- Health / finance / legal: data_accuracy, hallucination, security, inappropriate_content, escalation.
- E-commerce: data_accuracy, completeness, conciseness, language.
- FAQs / informational: comparison, completeness, fluency, language.
- Critical cases: security, hallucination, bias are usually a good baseline.
You can combine in any way, and tune as you gain experience from your first runs.
Re-evaluating and Score Overrides
You can run multiple evaluations over time on the same Run — with different evaluators activated, or simply to re-score. Each evaluation is stored as an independent snapshot. Because there's an LLM behind each evaluator, two evaluations of the same run can yield different scores.
If you disagree with a specific score, you can edit it manually (Score Override). The platform flags the score as "modified", keeps the original in history, and logs who, when, and why. Auditability stays intact. The full list of overrides lives at Execution → Score Overrides.
Next step
Once the Run is evaluated, the next step is interpreting the results. That's covered in the Reports & dashboard section.